Для работы любого современного браузера, в том числе я от разработчика Яндекс, используется cache-память. Эта технология позволяет уменьшить расход интернет трафика, увеличить производительность обозревателя, повысить удобство работы пользователей. Наиболее значимой функций кеша является возможность смотреть видео и слушать музыку онлайн. В данной статье описывается, где находится кэш-память браузера от Яндекс.
Содержание
- Очистка через интерфейс браузера
- Папка cache
- Веб-архивы Интернета: как искать удалённую информацию и восстанавливать сайты
- Какие существуют веб-архивы Интернета
- web.archive.org
- archive.md
- web-arhive.ru
- Поиск сразу по всем Веб-архивам
- Что делать, если удалённая страница не сохранена ни в одном из архивов?
- Как полностью скачать сайт из веб-архива
- Как скачать все изменения страницы из веб-архива
- Как узнать все страницы сайта, которые сохранены в веб-архиве
- Связанные статьи:
- Кэш Google, который всё помнит
- Web-archive, в котором вся история интернета
- Кэш Яндекса, почему бы и нет
- Кэш Baidu, пробуем азиатское
- CachedView.com, специализированный поисковик
- Archive.is, для собственного кэша
- Кэши других поисковиков, мало ли
- Кэш браузера, когда ничего не помогает
- Пробуем скачать файл страницы напрямую с сервера
- Что делать, если вообще ничего не помогло
- Как посмотреть кэш страницы сайта?
- Просмотр кэша страницы вручную
Очистка через интерфейс браузера
Из-за проблем с кешем веб-обозреватель начинает медленно работать. Также он может и вовсе перестать показывать видео или воспроизводить музыку. Подобная неприятная проблема решается достаточно просто – очисткой.
Для того чтобы почистить кэш, пользователям нет необходимо знать, где он располагается. Это можно быстро сделать с помощью стандартных инструментов интернет-обозревателя. Выполните несколько простых шагов, описанных в инструкции:
- Запустите обозреватель от Яндекс.
- Откройте главную панель управления с помощью специального значка в «шапке» окна.
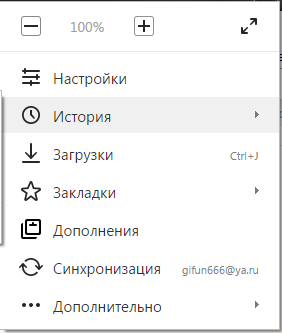
- Наведите курсор на вкладку с названием «История» («History»).
- В раскрывшемся списке второго уровня необходимо открыть диспетчер истории (history manager). Вы также можете вызвать диспетчер, воспользовавшись комбинацией клавиш «Control» + «H».
- В открывшемся окне требуется кликнуть по гиперссылке «Clear history…» («Очистить историю…»). Она располагается в правой части страницы.
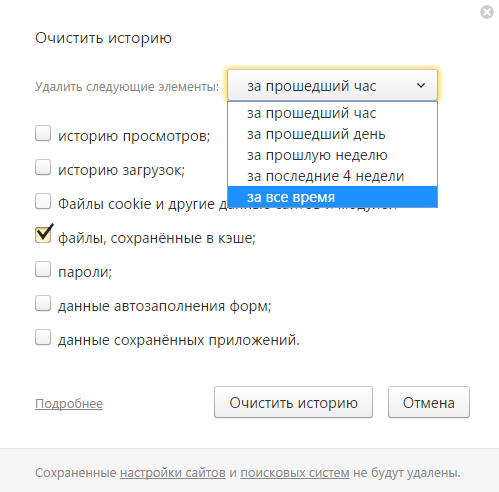
- В небольшом всплывающем окне откроется специальный интерфейс браузера для работы с сохраненными на жестком диске данными.
- В ниспадающем списке требуется выбрать промежуток времени для удаления. Лучше выбирать пункт «За все время».
Таким образом, все проблемы с кешем будут устранены. Далее в статье описывается, где найти локальный файл, в который сохраняются все данные из интернета.
Папка cache
Если по каким-то причинам вам понадобились сами файлы с кешем, вы можете найти их в служебной директории обозревателя Yandex. Эта директория находится в системном каталоге AppData, который по умолчанию скрыт от просмотра. Это значит, что без предварительной настройки Проводника Windows пользователи не смогут открыть эту папку и работать с ней.
Никаких сложных изменений в работу персонального компьютера вносить не потребуется. Просто следуйте представленной инструкции:
- Запустите Проводник Виндовс.
- На панели управления Проводником выберите раздел «Упорядочить».
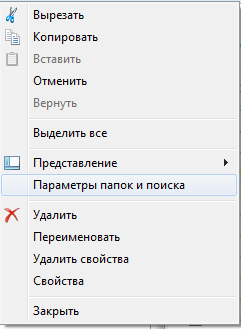
- Отметьте галкой опцию «Кэш» («Cahce») и нажмите «Очистить» («Clear»).
- В ниспадающем меню раскройте категорию «Параметры папок».
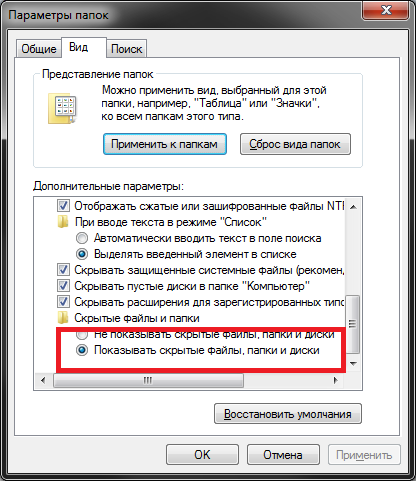
- Откроется новое окно с тремя вкладками. Перейдите по закладке «Вид».
- Пролистайте список, расположенный в разделе «Дополнительные параметры», до самого конца.
- В категории «Скрытые файлы» требуется установить отметку напротив опции «Показывать скрытые…».
- Теперь откройте содержимое жесткого диска, на котором установлена ваша операционная система. Как правило, это диск С.
- Далее необходимо открыть папку «Users» или «Пользователи», а в ней найти собственный каталог. Его название совпадает с вашим именем пользователя в Windows.
- Откройте «AppData», затем «Local». Найдите раздел с названием «Yandex», а в нем «YandexBrowser».
- Перейдите в директорию «User Data», затем в «Default».
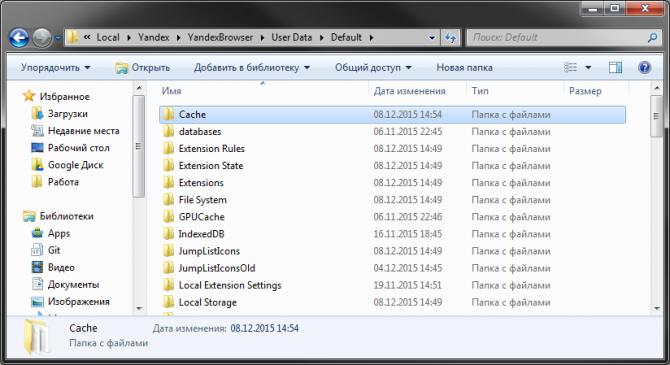
- Нажмите «Применить» и «Ok».
- Здесь расположена искомая папка Cache. Вы можете удалить ее или, к примеру, скопировать ее содержимое.
Веб-архивы Интернета: как искать удалённую информацию и восстанавливать сайты
В этой статье мы рассмотрим Веб Архивы сайтов или Интернет архивы: как искать удалённую с сайтов информацию, как скачать больше несуществующие сайты и другие примеры и случаи использования.
Принцип работы всех Интернет Архивов схожий: кто-то (любой пользователь) указывает страницу для сохранения. Интернет Архив скачивает её, в том числе текст, изображения и стили оформления, а затем сохраняет. По запросу сохранённые страницу могут быть просмотрены из Интернет Архива, при этом не имеет значения, если исходная страница изменилась или сайт в данный момент недоступен или вовсе перестал существовать.
Многие Интернет Архивы хранят несколько версий одной и той же страницы, делая её снимок в разное время. Благодаря этому можно проследить историю изменения сайта или веб-страницы в течение всех лет существования.
В этой статье будет показано, как находить удалённую или изменённую информацию, как использовать Интернет Архивы для восстановления сайтов, отдельных страниц или файлов, а также некоторые другие случае использования.
Wayback Machine — это название одного из популярного веб архива сайтов. Иногда Wayback Machine используется как синоним «Интернет Архив».
Какие существуют веб-архивы Интернета
Я знаю о трёх архивах веб-сайтов (если вы знаете больше, то пишите их в комментариях):
- https://web.archive.org/
- http://archive.md/ (также использует домены http://archive.ph/ и http://archive.today/)
- http://web-arhive.ru/
web.archive.org
Этот сервис веб архива ещё известен как Wayback Machine. Имеет разные дополнительные функции, чаще всего используется инструментами по восстановлению сайтов и информации.
Для сохранения страницы в архив перейдите по адресу https://archive.org/web/ введите адрес интересующей вас страницы и нажмите кнопку «SAVE PAGE».

Для просмотра доступных сохранённых версий веб-страницы, перейдите по адресу https://archive.org/web/, введите адрес интересующей вас страницы или домен веб-сайта и нажмите «BROWSE HISTORY»:

В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.

Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.


Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:

Кроме календаря доступна следующие страницы:
- Collections — коллекции. Доступны как дополнительные функции для зарегистрированных пользователей и по подписке
- Changes
- Summary
- Site Map
Changes
«Changes» — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:

И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
Summary
В этой вкладке статистика о количестве изменений MIME-типов.

Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Поиск по Интернет архиву
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:
Показ страницы на определённую дату
Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.
archive.md
Адреса данного Архива Интернета:
- http://archive.md
- http://archive.ph/
- http://archive.today/
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы
Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
Дату можно продолжить далее, указав часы, минуты и секунды:
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
- http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
- http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
- http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
web-arhive.ru
Архив интернет (Web archive) — это бесплатный сервис по поиску архивных копий сайтов. С помощью данного сервиса вы можете проверить внешний вид и содержимое страницы в сети интернет на определённую дату.
На момент написания, этот сервис, вроде бы, нормально не работает («Database Exception (#2002)»). Если у вас есть по нему какие-то новости, то пишите их в комментариях.
Поиск сразу по всем Веб-архивам
Может так случиться, что интересующая страница или файл отсутствует в веб архиве. В этом случае можно попытаться найти интересующую сохранённую страницу в другом Архиве Интернета. Специально для этого я сделал довольно простой сервис, который для введённого адреса даёт ссылки на снимки страницы в рассмотренных трёх архивах.
Адрес сервиса: https://suip.biz/ru/?act=web-arhive
Что делать, если удалённая страница не сохранена ни в одном из архивов?
Архивы Интернета сохраняют страницы только если какой-то пользователь сделал на это запрос — они не имеют функции обходчиков и ищут новые страницы и ссылки. По этой причине возможно, что интересующая вас страница оказалась удалено до того, как была сохранена в каком-либо веб-архиве.
Тем не менее можно воспользоваться услугами поисковых движков, которые активно ищут новые ссылки и оперативно сохраняют новые страницы. Для показа страницы из кэша Google нужно в поиске Гугла ввести
cache:URL
Например:
cache:https://hackware.ru/?p=6045
Если ввести подобный запрос в поиск Google, то сразу будет открыта страница из кэша.
Для просмотра текстовой версии можно использовать ссылку вида:
- http://webcache.googleusercontent.com/search?q=cache:URL&strip=1&vwsrc=0
Для просмотра исходного кода веб страницы из кэша Google используйте ссылку вида:
- http://webcache.googleusercontent.com/search?q=cache:URL&strip=0&vwsrc=1
Например, текстовый вид:
- http://webcache.googleusercontent.com/search?q=cache:https://hackware.ru/?p=6045&strip=1&vwsrc=0
Исходный код:
- http://webcache.googleusercontent.com/search?q=cache:https://hackware.ru/?p=6045&strip=0&vwsrc=1
Как полностью скачать сайт из веб-архива
Если вы хотите восстановить удалённый сайт, то вам поможет программа Wayback Machine Downloader.
Программа загрузит последнюю версию каждого файла, присутствующего в Архиве Интернета Wayback Machine, и сохранить его в папку вида ./websites/example.com/. Она также пересоздаст структуру директорий и автоматически создаст страницы index.html чтобы скаченный сайт без каких либо изменений можно было бы поместить на веб-сервер Apache или Nginx.
Об установке программы и дополнительных опциях смотрите на странице https://kali.tools/?p=5211
Пример скачивания полной копии сайта suip.biz из веб-архива:
wayback_machine_downloader https://suip.biz
Структура скаченных файлов:
Локальная копия сайта, обратите внимание на провайдера Интернет услуг:
Как скачать все изменения страницы из веб-архива
Если вас интересует не весь сайт, а определённая страница, но при этом вам нужно проследить все изменения на ней, то в этом случае используйте программу Waybackpack.
waybackpack suip.biz -d ./suip.biz-copy —to-date 2017 —follow-redirects
Структура директорий:
Чтобы для указанного сайта (hackware.ru) вывести список всех доступных копий в веб-архиве (—list):
waybackpack hackware.ru —list
Как узнать все страницы сайта, которые сохранены в веб-архиве
Для получения ссылок, которые хранятся в Архиве Интернета, используйте программу waybackurls.
Эта программа извлекает все URL указанного домена, о которых знает Wayback Machine. Это можно использовать для быстрого составления карты сайта.
Чтобы получить список всех страниц о которых знает Wayback Machine для домена suip.biz:
echo suip.biz | waybackurls
Предыдущие три программы рассмотрены совсем кратко. Дополнительную информацию об их установке и об имеющихся опциях вы сможете найти по ссылкам на карточки этих программ.
Ещё парочка программ, которые работают с архивом интернета:
- https://github.com/relrelb/wayback-downloader
- https://github.com/erlange/wbm-dl
Связанные статьи:
- Инструкция по использованию HTTrack: создание зеркал сайтов, клонирование страницы входа (77.5%)
- badKarma: Продвинутый набор инструментов для сетевой разведки (77.5%)
- Обход файерволов веб приложений Cloudflare, Incapsula, SUCURI (76%)
- FinalRecon: простой и быстрый инструмент для сбора информации о сайте, работает и на Windows (76%)
- Сбор информации о владельце сайта. Поиск сайтов одного лица (53.4%)
- Продвинутый поиск в Яндекс (RANDOM — 29.1%)
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
Где http://www.iphones.ru/ надо заменить на адрес искомого сайта.
Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
Кэш Baidu, пробуем азиатское
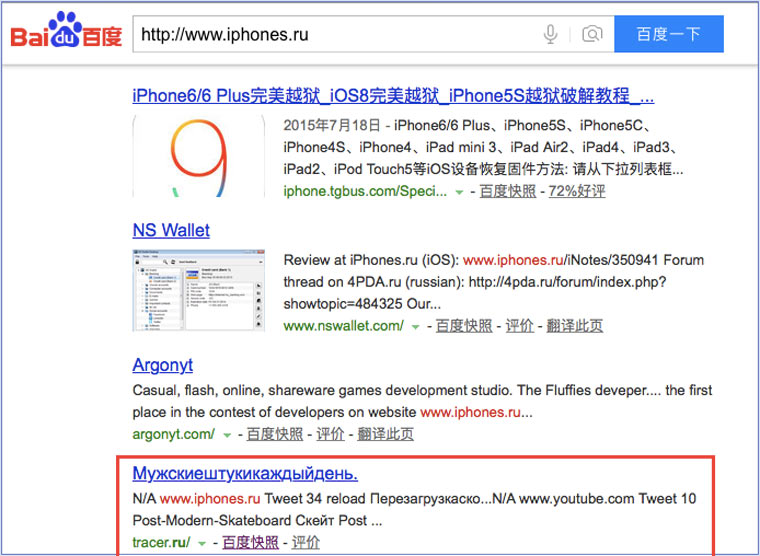
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
CachedView.com, специализированный поисковик
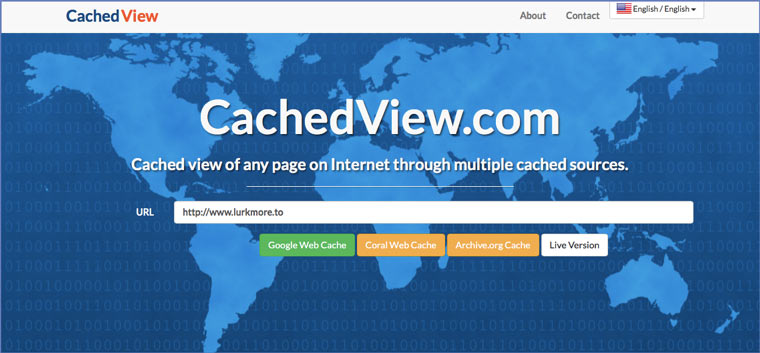
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
Archive.is, для собственного кэша
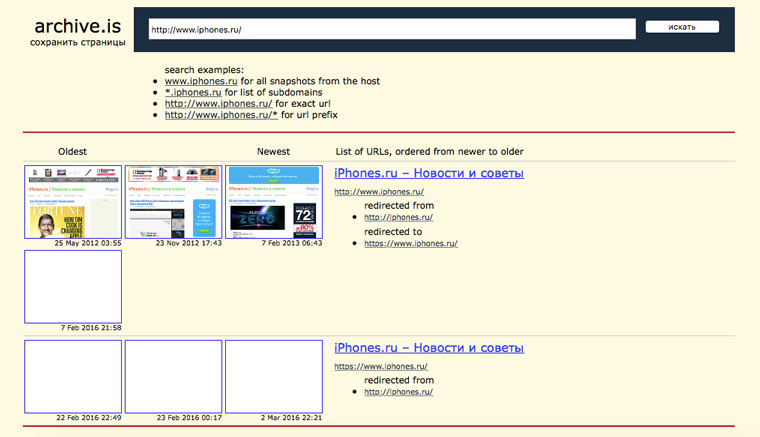
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
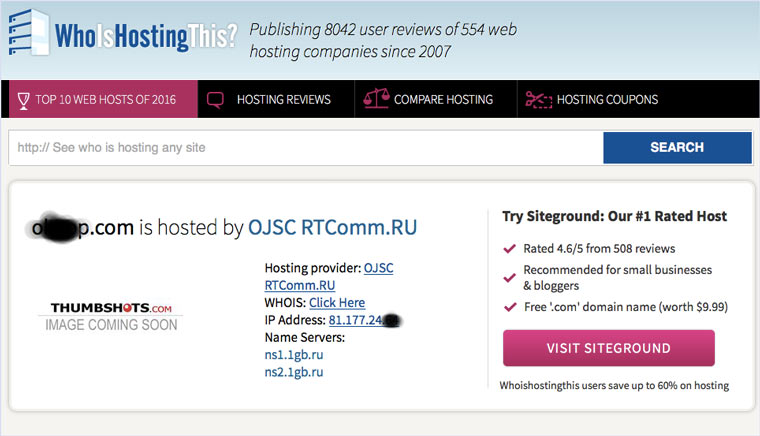
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
О других методах поиска читайте в статье 12 способов найти владельца сайта и узнать про него все.
А о сборе информации про людей читайте в статьях 9 сервисов для поиска информации в соцсетях и 15 фишек для сбора информации о человеке в интернете.
(21 голосов, общий 4.81 из 5)
🤓 Хочешь больше? Подпишись на наш Telegramнаш Telegram. … и не забывай читать наш Facebook и Twitter 🍒 iPhones.ru Сервисы и трюки, с которыми найдётся ВСЁ. Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход. Всё, что попадает в интернет,…
Смотрим кэшированные документы
Иногда вы делаете кой-какие изменения на своём сайте (с целью улучшения SEO-показателей) и, что весьма логично, вам хочется узнать, как поисковики отнесутся к этим изменениям — улучшат/ухудшат ранжирование страниц(ы) или же всё оставят без изменений?
Для того, чтобы узнать, «увидели» или нет поисковые роботы внесённые вами изменения, необходимо проверить «свежесть» страницы вашего сайта в поисковом индексе. Т.е. нужно понять — обновилась ли страница в кэше поисковика после ваших изменений или нет?
Кэш поисковой системы — это почти то же самое, что и её индекс. Это копии документов сайта от определённого числа (обычно, от момента последнего посещения поисковым роботом), которые хранятся у поисковиков. Чем-то он напоминает кэш-память браузера.
Как посмотреть кэш страницы сайта?
Все основные поисковики охотно предоставляют возможность просмотреть кэш веб-документов в их индексе. Сделать это можно вручную или по-быстрому.
По-быстрому — проще всего при помощи специальных сервисов и дополнений для браузеров, почитайте эти статьи (там всё просто):
- RDS bar в Хроме.
- Page Promoter в Firefox.
Но и вручную уметь это делать также полезно, потому как плагины иногда глючат, сервисы недоступны и т.п.
Да, и увидеть кэш документа не получится, если он вообще не проиндексирован. Про то, как проверить индексацию в Яндексе, Гугле, Mail.ru и Bing.com — .
Просмотр кэша страницы вручную
В Google
На странице с выдачей (SERP) следует навести мышку на конкретный результат выдачи и кликнуть «Сохраненная копия»:
Просмотр кэшированного документа в Google
Естественно, запрос можно сформировать как угодно. На картинке приведён пример просмотра кэша конкретной страницы — http://web-ru.net/category/internet/.
Интересно, что прямо сейчас после клика по ссылке «Сохраненная копия» меня перекинуло на документ 404-й ошибки в Google:
404 в Google
Бывает и такое. Но, как правило, это временное явление. Обычно же просмотр страницы из кэша выглядит как-нибудь так. Т.е. он представляет из себя html-фрейм, в который загружен весь сайт.
У каждой из этих 4-х поисковых систем сверху можно обнаружить надпись вроде такой «по состоянию на 9 окт 2012 15:13:22 GMT». Т.е. отображается веб-страница такой, какой она была 9 октября 2012 года.
Кэш в Яндексе
Смысл тот же: вводим запрос, наводим курсор на один из результатов выдачи и кликаем на «Копия»:
Посмотрим кэш страницы в Яндекс
Для Bing.com
Нужно кликнуть на маленькую стрелочку, расположенную около URL-адреса страницы:
Кэш документав Bing.com
В Mail.ru
В этой поисковой системе лучше смотреть кэш отдельных страниц, а не, например, категорий. Просто потому что в Мэйле при запросе, содержащем URL категории, могут быть выведены ссылки на несколько статей этой категории, а не на саму категорию. Хотя Mail.ru как поисковик пока особо не интересен, и можно об этом вообще не думать. Ну а в целом, всё то же:
Кэш документа сайта в Mail.ru
Кстати, если в Гугле, Яндексе и Bing ввести «человеческий» запрос и посмотреть кэшированный документ, то этот запрос будет выделен на открытом сайте жёлтым цветом. Примерно так:
Выделенный запрос в кэше страницы в Гугле
Это может быть способом посмотреть, например, как оптимизированы тексты на сайтах ваших конкурентов
Таким образом, зная дату и время занесения страницы в кэш Google, Yandex и т.д. можно понять, известно ли поисковой системе о произошедших на ней изменениях или пока ещё нет.
Loading… Случайные публикации:
- Как сделать динамический сайдбар в WordPress и включить виджеты?…много чего ещё. Сайдбары бывают практически у всех сайтов (удобно ведь..).
- Информер Яндекс Метрики. Настройка…астройка информера Яндекс Метрики Для того, чтобы его настраивать, надо
- Топовые продажи сайтов в сентябре 2017…ирайтинга с оборотом в 36 миллионов рублей это биржа copylancer.ru. Не часто продаются
- Как установить счетчик Гугл Аналитикс на сайт WordPressПри работе над своим сайтом, очень важно знать статистику сайта. Это позво…
- Рекламная сеть LuckyAds выводит рынок нативной рекламы на новый уровень!…оекты, являющиеся лидерами в своих сегментах. Мы будем рады



