| |
Необходимо перенести содержимое этой статьи в статью «FLOPS». Вы можете помочь проекту, объединив статьи. В случае необходимости обсуждения целесообразности объединения, замените этот шаблон на шаблон {{к объединению}} и добавьте соответствующую запись на странице Википедия: К объединению. Пожалуйста, также проверьте историю правок. |
| |
Эта статья или раздел нуждается в переработке. Пожалуйста, улучшите статью в соответствии с правилами написания статей. |
Терафлопс (TFLOPS) — величина, используемая для измерения производительности компьютеров, показывающая, сколько операций с плавающей запятой в секунду выполняет данная вычислительная система. 1 терафлопс = 1 триллион операций в секунду = 1000 миллиардов операций в секунду. Обычно имеются в виду операции над плавающими числами размера 64 бита в формате IEEE 754.
TFLOPS = 1012 FLOPS (= 103 GFLOPS)
При измерении производительности кластеров и суперкомпьютеров часто используется 2 варианта: пиковая производительность — теоретический предел производительности (выражаемый через операции с плавающий точкой) для данных процессоров и максимальная производительность, которую данный кластер или компьютер достигает при решении практических задач. В качестве эталонной задачи часто выступает задача решения системы СЛАУ методом LU-разложения. Для измерений на кластерах используется реализация HPL — High performance linpack.
Чтобы найти пиковую производительность ЭВМ R, терафлопс, нужно тактовую частоту F, МГц, умножить на число процессоров (процессорных ядер) n, домножить на количество инструкций с плавающей запятой на такт (4 для процессоров Core2 — 2 операции Float Multiple Add; 8 для процессоров с AVX) и поделить на 1000000:
F × n × 4·10−6 = R
Например, суперкомпьютер eServer Blue Gene Solution (на май 2008 года был самым производительным на планете), который работает в Ливерморской национальной лаборатории, штат Калифорния, США, обладает пиковой производительностью 596,4 терафлопс. Максимальная производительность — 478,2 терафлопс — составляет 80 % от пиковой. Производитель — американская корпорация IBM.
Эта суперЭВМ собрана на базе 212992 процессоров PowerPC 440, тактовая частота каждого из которых 700 МГц. Его производительность:
700 МГц × 212992 процессоров × 4·10−6 = 596,4 трлн операций в секунду = 596,4 терафлопс.
В общем случае, соотношение максимальной и пиковой производительности варьируется от 60 % до 83 %, поэтому по указанной формуле можно вычислять лишь пиковую производительность суперЭВМ. Так, например, пиковая производительность компьютера на базе четырехъядерного процессора AMD Phenom 9500 sAM2+ с тактовой частотой 2,2 ГГц равна:
2200 МГц × 4 ядра × 4·10−6 = 3,52 млрд операций в секунду = 0,0352 терафлопс.
Для четырехъядерного процессора Core 2 Quad Q6600:
2400 МГц × 4 ядра × 4·10−6 = 3,84 млрд операций в секунду = 0,0384 терафлопс.
Кроме того, AMD представила вычислительную систему FireStream 9250, занимающую один разъем PCI, общая производительность которой превосходит терафлопс, но только на 32-х разрядных данных, тогда как для суперкомпьютеров принято считать производительность на 64-х разрядных данных.
На данный момент (июнь 2011) самый мощный суперкомпьютер K computer, занимает первую строчку в рейтинге суперкомпьютеров, его пиковая производительность составляет 11,280 петафлопс, а максимальная 10,510 петафлопс().
1000 терафлопс = 1 петафлопс.
Содержание
См.также
- FLOPS
- Компьютер
- Суперкомпьютер

Эти сверхмашины могут выполнять сложнейшие задачи и по своим характеристикам превосходят большинство компьютеров, с которыми мы сталкиваемся в обычной жизни. И хотя суперкомпьютеры до сих пор кажутся чем-то далеким, мы все чаще пользуемся результатами их работы: от поиска в интернете и прогнозов погоды до новейших лекарств и самолетов.
В 2019 году холдинг «Росэлектроника» создал новый суперкомпьютер «Фишер» для Российской академии наук. Разработка Ростеха поможет физикам в решении задач молекулярной динамики. Рассказываем о том, что такое супер-ЭВМ и где они применяются.
Супер-ЭВМ: квадриллион операций в секунду
Точного определения, что такое «суперкомпьютер», не существует. Компьютерная индустрия находится в постоянном развитии, и сегодняшние супермашины завтра уже будут далеко позади. Можно сказать, что суперкомпьютер – это очень мощный компьютер, который способен обрабатывать гигантские объемы данных и производить сложнейшие расчеты. Там, где человеку для вычислений нужны десятки тысяч лет, суперкомпьютер обойдется одной секундой. И если в 1980-х суперкомпьютером в шутку предлагали называть любые ЭВМ, весящие более тонны, то сегодня они чаще всего представляют собой большое количество серверных компьютеров с высокой производительностью, объединенных высокоскоростной сетью.
Современный суперкомпьютер – это огромное устройство, состоящее из модулей памяти, процессоров, плат, объединенных в вычислительные узлы, связанные между собой сетью. Управляющая система распределяет задания, контролирует загрузку и отслеживает выполнение задач. Системы охлаждения и бесперебойного питания обеспечивают беспрерывную работу супер-ЭВМ. Весь комплекс может занимать значительные площади и потреблять огромное количество энергии.
Производительность суперкомпьютеров измеряется во флопсах – количестве операций с плавающей запятой, которые система может выполнять в секунду. Так, например, один из первых суперкомпьютеров, созданный в 1975 году американский Cray-1, мог совершать 133 миллиона операций в секунду, соответственно, его пиковая мощность составляла 133 мегафлопс. А самый мощный на июнь 2019 года суперкомпьютер Summit Ок-Риджской национальной лаборатории обладает вычислительной мощностью 122,3 петафлопс, то есть 122,3 квадриллиона операций в секунду.

Суперкомпьютер «Ломоносов-2». Фото: «Т-Платформы»
Существует международный рейтинг топ-500, который с 1993 года ранжирует самые мощные вычислительные машины мира. Данные рейтинга обновляются два раза в год, в июне и ноябре. В 2019 году в первую десятку входят суперкомпьютеры США, Китая, Швейцарии, Японии и Германии. Единственный отечественный суперкомпьютер в первой сотне рейтинга − «Ломоносов-2» из Научно-исследовательского вычислительного центра МГУ производительностью 2,478 терафлопс, занявший в июне 2019 года 93-е место.
Чтобы определить мощность суперкомпьютера, или, как его еще называют в английском языке, «числодробилки» (number cruncher), используется специальная тестовая программа, которая предлагает машинам решить одну и ту же задачу и подсчитывает, сколько времени ушло на ее выполнение.
Что могут «числодробилки»
Первые суперкомпьютеры создавались для военных, которые применяли их в разработках ядерного оружия. В современную цифровую эпоху сложные вычисления требуются во многих областях человеческой деятельности. Суперкомпьютеры незаменимы там, где применяется компьютерное моделирование, где в реальном времени обрабатываются большие объемы данных и где задачи решаются методом простого перебора огромного множества значений. «Числодробилки» работают в статистике, криптографии, биологии, физике, помогают предсказывать погоду и глобальные изменения климата.

С развитием информационных технологий и применением их на практике появились новые направления на стыке информатики и прикладных наук – вычислительная биология, вычислительная химия, вычислительная лингвистика и многие другие. Суперкомпьютеры используются для создания искусственных нейросетей и искусственного интеллекта.
Именно сверхмощным компьютерам мы обязаны появлением точных прогнозов погоды. Суперкомпьютеры совершили революцию в медицине, в частности – в диагностике и лечении рака. С их помощью обрабатываются миллионы диагнозов и историй болезней, выявляются новые закономерности развития заболевания и вырабатываются новые способы лечения. Сверхумные машины применяются для расчета химических соединений, на основе которых изготавливаются новые лекарства. Масштабные расчеты помогают в сферах, связанных с проектированием: строительстве, машиностроении, авиастроении и других.
Суперкомпьютер с «бесконечным» масштабированием
В эпоху цифровой экономики и всеобщей цифровизации вычислениям отводится ключевое место. На создание суперкомпьютеров крупнейшие государства выделяют многомиллионные суммы. Эти вложения должны быть постоянными, так как производительность суперкомпьютеров удваивается каждые полтора года. Сегодня Россия находится только в начале построения национальной сети сверхмощных машин.
Структуры Ростеха в числе прочих российских предприятий вносят свой вклад в создание отечественной киберинфраструктуры. В сентябре 2019 года холдинг «Росэлектроника» объявил о запуске суперкомпьютера «Фишер» с пиковой производительностью 13,5 Тфлопс и практически неограниченными возможностями для масштабирования. Машина разработана специалистами холдинга для Объединенного института высоких температур Российской академии наук (ОИВТ РАН). Новый суперкомпьютер поможет ученым-физикам в создании цифровых моделей веществ и прогнозе поведения материалов в экстремальных состояниях.
Суперкомпьютер «Фишер» состоит из 24 вычислительных узлов с 16-ядерными процессорами. Для улучшения терморегуляции вычислительного кластера «Фишера» используется иммерсионная (погружная) система охлаждения. Благодаря ей суперкомпьютер не требует специально оборудованных помещений и может работать при температурах от ‒50 °С до +50 °С. Подобные системы охлаждения применяются сегодня на самых высокопроизводительных машинах мира.

«Фишер» создан на основе коммуникационной сети «Ангара» − первого российского интерконнекта, позволяющего объединять группы машин в мощные вычислительные кластеры. С помощью «Ангары» можно соединять тысячи компьютеров разных производителей и с разной архитектурой центральных процессоров. Коммутаторное исполнение «Фишера» позволяет компоновать компьютеры с большей плотностью и в целом облегчает сборку и использование всей системы за счет уменьшения числа кабелей. Модульный характер системы позволяет масштабировать мощность «Фишера» под любые нужды.
Ученые из ОИВТ РАН уже несколько лет используют суперкомпьютер DESMOS мощностью 52,24 Тфлопс, созданный на базе предыдущего поколения сети «Ангара». Его вычислительные мощности оказались настолько востребованы, что было принято решение о создании «младшего брата» этого суперкомпьютера уже на базе нового поколения коммутационной сети.
 Как известно, FLOPS – это единица измерения вычислительной мощности компьютеров в (попугаях) операциях с плавающей точкой, которой часто пользуются, чтобы померить у кого больше. Особенно важно померяться FLOPS’ами в мире Top500 суперкомпьютеров, чтобы выяснить, кто же среди них самый-самый. Однако, предмет измерения должен иметь хоть какое-нибудь применение на практике, иначе какой смысл его замерять и сравнивать. Поэтому для выяснения возможностей супер- и просто компьютеров существуют чуть более приближенные к реальным вычислительным задачам бенчмарки, например, SPEC: SPECint и SPECfp. И, тем не менее, FLOPS активно используется в оценках производительности и публикуется в отчетах. Для его измерения давно уже использовали тест Linpack, а сейчас применяют открытый стандартный бенчмарк из LAPACK. Что эти измерения дают разработчикам высокопроизводительных и научных приложений? Можно ли легко оценить производительность реализации своего алгоритма в FLOPSaх? Будут ли измерения и сравнения корректными? Обо всем этом мы поговорим ниже.
Как известно, FLOPS – это единица измерения вычислительной мощности компьютеров в (попугаях) операциях с плавающей точкой, которой часто пользуются, чтобы померить у кого больше. Особенно важно померяться FLOPS’ами в мире Top500 суперкомпьютеров, чтобы выяснить, кто же среди них самый-самый. Однако, предмет измерения должен иметь хоть какое-нибудь применение на практике, иначе какой смысл его замерять и сравнивать. Поэтому для выяснения возможностей супер- и просто компьютеров существуют чуть более приближенные к реальным вычислительным задачам бенчмарки, например, SPEC: SPECint и SPECfp. И, тем не менее, FLOPS активно используется в оценках производительности и публикуется в отчетах. Для его измерения давно уже использовали тест Linpack, а сейчас применяют открытый стандартный бенчмарк из LAPACK. Что эти измерения дают разработчикам высокопроизводительных и научных приложений? Можно ли легко оценить производительность реализации своего алгоритма в FLOPSaх? Будут ли измерения и сравнения корректными? Обо всем этом мы поговорим ниже.
Давайте сначала немного разберемся с терминами и определениями. Итак, FLOPS – это количество вычислительных операций или инструкций, выполняемых над операндами с плавающей точкой (FP) в секунду. Здесь используется слово «вычислительных», так как микропроцессор умеет выполнять и другие инструкции с такими операндами, например, загрузку из памяти. Такие операции не несут полезной вычислительной нагрузки и поэтому не учитываются.
Значение FLOPS, опубликованное для конкретной системы, – это характеристика прежде всего самого компьютера, а не программы. Ее можно получить двумя способами – теоретическим и практическим. Теоретически мы знаем сколько микропроцессоров в системе и сколько исполняемых устройств с плавающей точкой в каждом процессоре. Все они могут работать одновременно и начинать работу над следующей инструкцией в конвеере каждый цикл. Поэтому для подсчета теоретического максимума для данной системы нам нужно только перемножить все эти величины с частотой процессора – получим количество FP операций в секунду. Все просто, но такими оценками пользуются, разве что заявляя в прессе о будущих планах по построению суперкомпьютера.
Практическое измерение заключается в запуске бенчмарка Linpack. Бенчмарк осуществляет операцию умножения матрицы на матрицу несколько десятков раз и вычисляет усредненное значение времени выполнения теста. Так как количество FP операций в имплементации алгоритма известно заранее, то разделив одно значение на другое, получим искомое FLOPS. Библиотека Intel MKL (Math Kernel Library) содержит пакет LAPAСK, — пакет библиотек для решения задач линейной алгебры. Бенчмарк построен на основе этого пакета. Cчитается, что его эффективность находится на уровне 90% от теоретически возможной, что позволяет бенчмарку считаться «эталонным измерением». Отдельно Intel Optimized LINPACK Benchmark для Windows, Linux и MacOS можно качать , либо взять в директории composerxe/mkl/benchmarks, если у вас установлена Intel Parallel Studio XE.
Очевидно, что разработчики высокопроизводительных приложений хотели бы оценить эффективность имплементации своих алгоритмов, используя показатель FLOPS, но уже померянный для своего приложения. Сравнение измеренного FLOPS с «эталонным» дает представление о том, насколько далека производительность их алгоритма от идеальной и каков теоретический потенциал ее улучшения. Для этого всего-навсего нужно знать минимальное количество FP операций, требуемое для выполнения алгоритма, и точно измерить время выполнения программы (ну или ее части, выполняющей оцениваемый алгоритм). Такие результаты, наряду с измерениями характеристик шины памяти, нужны для того, чтобы понять, где реализация алгоритма упирается в возможности аппаратной системы и что является лимитирующим фактором: пропускная способность памяти, задержки передачи данных, производительность алгоритма, либо системы.
Ну а теперь давайте покопаемся в деталях, в которых, как известно, все зло. У нас есть три оценки/измерения FLOPS: теоретическая, бенчмарк и программа. Рассмотрим особенности вычисления FLOPS для каждого случая.
Теоретическая оценка FLOPS для системы
Чтобы понять, как подсчитывается количество одновременных операций в процессоре, давайте взглянем на устройство блока out-of-order в конвеере процессора Intel Sandy Bridge.
Здесь у нас 6 портов к вычислительным устройствам, при этом, за один цикл (или такт процессора) диспетчером может быть назначено на выполнение до 6 микроопераций: 3 операции с памятью и 3 вычислительные. Одновременно могут выполняться одна операция умножения (MUL) и одна сложения (ADD), как в блоках x87 FP, так и в SSE, либо AVX. С учетом ширины SIMD регистров 256 бит мы может получить следующие результаты:
8 MUL (32-bit) и 8 ADD (32-bit): 16 SP FLOP/cycle, то есть 16 операций с плавающей точкой одинарной точности за один такт.
4 MUL (64-bit) и 4 ADD (64-bit): 8 DP FLOP/cycle, то есть 8 операций с плавающей точкой двойной точности за один такт.
Теоретическое пиковое значение FLOPS для доступного мне 1-сокетного Xeon E3-1275 (4 cores @ 3.574GHz) составляет:
16 (FLOP/cycle)*4*3.574 (Gcycles/sec)= 228 GFLOPS SP
8 (FLOP/cycle)*4*3.574 (Gcycles/sec)= 114 GFLOPS DP
Запуск бенчмарка Linpack
Запускам бенчмарк из пакета Intel MKL на системе и получаем следующие результаты (порезано для удобства просмотра):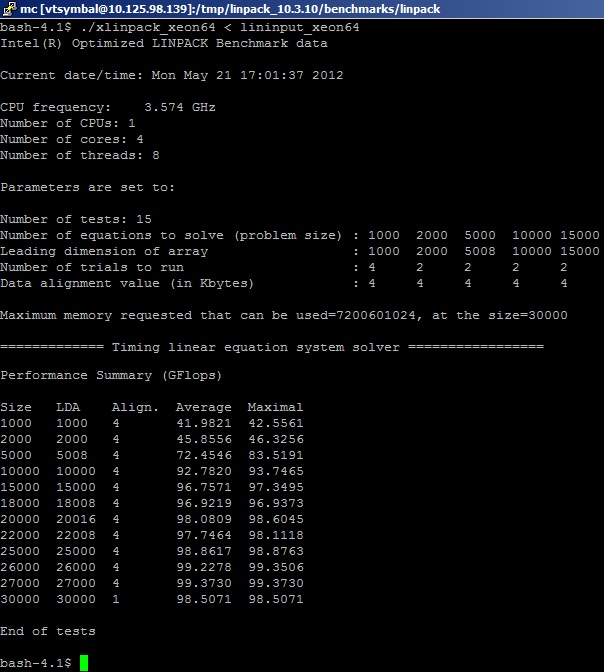
Здесь нужно сказать, как именно учитываются FP операции в бенчмарке. Как уже упоминалось, тест заранее «знает» количество операций MUL и ADD, которые необходимы для перемножения матриц. В упрощенном представлении: производится решение системы линейных уравнений Ax=b (несколько тысяч штук) путем перемножения плотных матриц действительных чисел (real8) размером MxK, а количество операций сложения и умножения, необходимых для реализации алгоритма, считается (для симметричной матрицы) Nflop = 2*(M^3)+(M^2). Вычисления производятся для чисел с двойной точностью, как и для большинства бенчмарков. Сколько операций с плавающей точкой действительно выполняется в реализации алгоритма, пользователей не волнует, хотя они догадываются, что больше. Это связано с тем, что выполняется декомпозиция матриц по блокам и преобразование (факторизация) для достижения максимальной производительности алгоритма на вычислительной платформе. То есть нам нужно запомнить, что на самом деле значение физических FLOPS занижено за счет неучитывания лишних операций преобразования и вспомогательных операций типа сдвигов.
Оценка FLOPS программы
Чтобы исследовать соизмеримые результаты, в качестве нашего высокопроизводительного приложения будем использовать пример перемножения матриц, сделанный «своими руками», то есть без помощи математических гуру из команды разработчиков MKL Performance Library. Пример реализации перемножения матриц, написанный на языке С, можно найти в директории Samples пакета Intel VTune Amplifier XE. Воспользуемся формулой Nflop=2*(M^3) для подсчета FP операций (исходя из базового алгоритма перемножения матриц) и померим время выполнения перемножения для случая алгоритма multiply3 при размере симметричных матриц M=4096. Для того, чтобы получить эффективный код, используем опции оптимизации –O3 (агрессивная оптимизация циклов) и –xavx (использовать инструкции AVX) С-компилятора Intel для того, чтобы сгенерировались векторные SIMD-инструкции для исполнительных устройств AVX. Компилятор нам поможет узнать, векторизовался ли цикл перемножения матрицы. Для этого укажем опцию –vec-report3. В результатах компиляции видим сообщения оптимизатора: «LOOP WAS VECTORIZED» напротив строки с телом внутреннего цикла в файле multiply.c.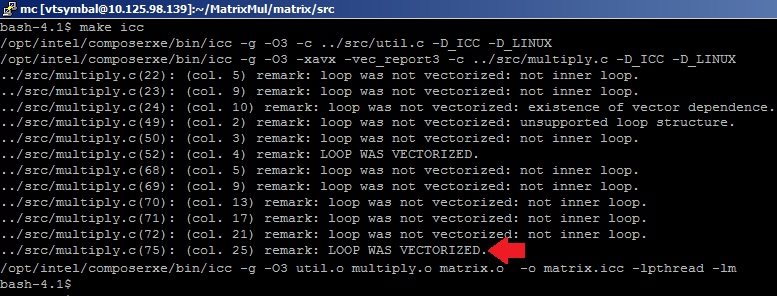
На всякий случай проверим, какие инструкции сгенерированы компилятором для цикла перемножения.
$icl –g –O3 –xavx –S
По тэгу __tag_value_multiply3 ищем нужный цикл — инструкции правильные.
$vi muliply3.s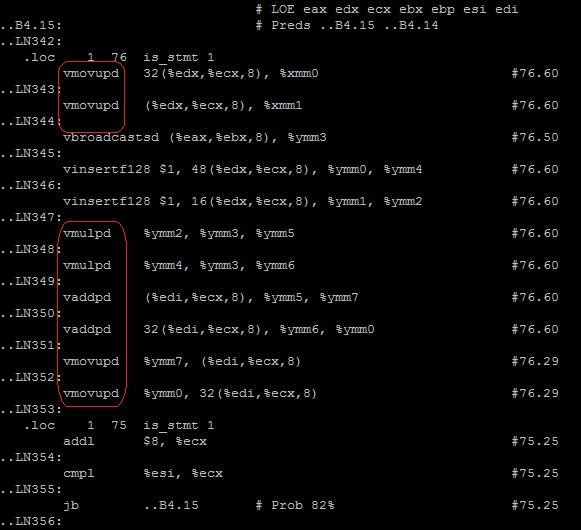
Результат выполнения программы (~7 секунд)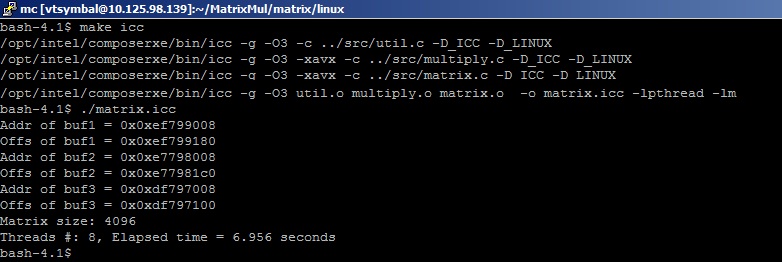
нам дает следующее значение FLOPS = 2*4096*4096*4096/7 = 19.6 GFLOPS
Результат, конечно, очень далек от того, что получается в Linpack, что объясняется исключительно квалификционной пропастью между автором статьи и разработчиками библиотеки MKL.
Ну, а теперь дессерт! Собственно то, ради чего я затеял свое исследование этой, вроде бы скучной и давно избитой, темы. Новый метод измерения FLOPS.
Измерение FLOPS программы
Существуют задачи в линейной алгебре, программную имплементацию решения которых очень сложно оценить в количестве FP операций, в том смысле, что нахождение такой оценки само является нетривиальной математической задачей. И тут мы, что называется, приехали. Как считать FLOPS для программы? Есть два пути, оба экспериментальных: трудный, дающий точный результат, и легкий, но обеспечивающий приблизительную оценку. В первом случае нам придется взять некую базовую программную имплементацию решения задачи, скомпилировать ее в ассемблерные инструкции и, выполнив их на симуляторе процессора, посчитать количество FP операций. Звучит так, что резко хочется пойти легким, но недостоверным путем. Тем более, что если ветвление исполнения задачи будет зависеть от входных данных, то вся точность оценки сразу поставится под сомнение.
Идея легкого пути состоит в следующем. Почему бы не спросить сам процессор, сколько он выполнил FP инструкций. Процессорный конвеер, конечно же, об этом не ведает. Зато у нас есть счетчики производительности (PMU – воттутпро них интересно), которые умеют считать, сколько микроопераций было выполнено на том или ином вычислительном блоке. С такими счетчиками умеет работать VTune Amplifier XE.
Несмотря на то, что VTune имеет множество встроенных профилей, специального профиля для измерения FLOPS у него пока нет. Но никто не мешает нам создать наш собственный пользовательский профиль за 30 секунд. Не утруждая вас основами работы с интерфейсом VTune (их можно изучить в прилагающимся к нему Getting Started Tutorial), сразу опишу процесс создания профиля и сбора данных.
- Создаем новый проект и указываем в качестве target application наше приложение matrix.
- Выбираем профиль Lightweight Hotspots (который использует технологию сэмплирования счетчиков процессора Hadware Event-based Sampling) и копируем его для создания пользовательского профиля. Обзываем его My FLOPS Analysis.
- Редактируем профиль, добавляем туда новые процессорные счетчики событий процессора Sandy Bridge (Events). На них остановимся чуть подробнее. В их названии зашифрованы исполнительные устройства (x87, SSE, AVX) и тип данных, над которыми выполнялась операция. Каждый такт процессора счетчики складывают количество вычислительных операций, назначенных на исполнение. На всякий случай мы добавили счетчики на все возможные операции с FP:
Нам остается только запустить анализ и подождать результатов. В полученных результатах переключаемся в Hardware Events viewpoint и копируем количетво events, собранных для функции multiply3: 34,648,000,000.
Далее мы просто подсчитываем значения FLOPS по формулам. Данные у нас были собраны для всех процессоров, поэтому умножение на их количество здесь не требуется. Операции данными двойной точности выполняются одновременно над четырмя 64-битными DP операндами в 256-битном регистре, поэтому умножаем на коэффициент 4. Данные с одинарной точностью, соответственно, умножаем на 8. В последней формуле не умножаем количество инструкций на коэффициент, так как операции сопроцессора x87 выполняются только со скалярными величинами. Если в программе выполняется несколько разных типов FP операций, то их количество, умноженное на коэффициенты, суммируется для получения результирующего FLOPS.
FLOPS = 4 * SIMD_FP_256.PACKED_DOUBLE / Elapsed Time
FLOPS = 8 * SIMD_FP_256.PACKED_SINGLE / Elapsed Time
FLOPS = (FP_COMP_OPS_EXE.x87) / Elapsed Time
В нашей программе выполнялись только AVX инструкции, поэтому в результатах есть значение только одного счетчика SIMD_FP_256.PACKED_DOUBLE.
Удостоверимся, что данные события собраны для нашего цикла в функции multiply3 (переключившись в Source View):
FLOPS = 4 *34.6Gops/7s = 19.7 GFlops
Значение вполне соответствует оценочному, подсчитанному в предыдущем пункте. Поэтому с достаточной долей точности можно говорить о том, что результаты оценочного метода и измерительного совпадают. Однако, существуют случаи, когда они могут не совпадать. При определенном интересе читателей, я могу заняться их исследованием и рассказать, как использовать более сложные и точные методы. А взамен очень хочется услышать о ваших случаях, когда вам требуется измерение FLOPS в программах.
Заключение
FLOPS – единица измерения производительности вычислительных систем, которая характеризует максимальную вычислительную мощность самой системы для операций с плавающей точкой. FLOPS может быть заявлена как теоретическая, для еще не существующих систем, так и измерена с помощью бенчмарков. Разработчики высокопроизводительных программ, в частности, решателей систем линейных дифференциальных уравнений, оценивают производительность реализации своих алгоритмов в том числе и по значению FLOPS программы, вычисленному с помощью теоретически/эмпирически известного количества FP операций, необходимых для выполнения алгоритма, и измеренному времени выполнения теста. Для случаев, когда сложность алгоритма не позволяет оценить количество FP операций алгоритма, их можно измерить с помощью счетчиков производительности, встроенных в микропроцессоры Intel.
Привет, Codeforces community!
Когда я начинал свою олимпиадную карьеру, я постоянно слышал что-то в стиле «некоторые операции выполняются быстрее других, некоторые типы данных медленнее, другие побыстрее». Я это понимал, понимал даже причины, но меня интересовала конкретика (т.е. «насколько быстрее»), которую я не получал. Теперь, когда я на втором курсе, имею некоторое представление о работе компудахтеров вычислительных машин, оптимизационной работе компилятора и возможных проблем при реализации бенчмарка, я могу попытаться всё-таки выяснить конкретные цифры, а заодно и поделиться ими. Думаю, новичкам это будет интересно, как и мне в своё время.
Всех заинтересованных прошу под кат 🙂 Начнём с краткого комментария по поводу флагов компиляции. g++ (как и clang++) поддерживает 4 уровня оптимизации (включаются флагами -O0, -O1, -O2, -O3) + флаги для конкретных видов оптимизаций. Как правило, на онлайн-джаджах используют -O2, но в мой бенчмарк запускается с флагом -O1. Почему? Ответ прост — -O2 слишком хорошо оптимизирует — сворачивает циклы, где (в нашем случае) не нужно, порою выбрасывает условия из циклов (исходя из своих эвристик) и так далее. Мы этого не хотим, поэтому и пользуемся -O1.
Перейдём, пожалуй, к методике замера. Тут я попытаюсь объяснить, почему бы не сделать просто что-то вроде…
begin_t = gettime(); a = b + c; end_t = gettime();
… и сказать что в end_t — begin_t теперь время, затраченное на одну операцию. Проблемы тут две — во-первых, сам вызов gettime() с большой долей вероятности займёт больше времени, чем выполнение нужной операции. Кроме того, разница времён получится ничтожно мала и при каждом запуске программы будет менятся в огромном (в процентном соотношении) диапазоне. Плохо.
Давайте тогда запустим много раз одно и то же:
begin_t = gettime(); for(int i = 0; i < MAX_ITER_N; i++) a = b + c; end_t = gettime();
Где MAX_ITER_N будет достаточно большим (порядка 107 — 109).
Уже получше, но есть несколько проблем. Во-первых, компилятор запросто может решить, что результат выполнения операции a = b + c всегда один и тот же, нечего выполнять это много раз, и вместо цикла выполнить операцию всего один раз. Более того, если после всех манипуляций ничего с переменной a не делать (вывод на экран, возврат из функции, что-либо другое), компилятор (даже при оптимизации -O0) выбросит вовсе строчки из цикла — как ни на что не влияющие операции. Есть еще несколько вариантов, где компилятор из благих побуждений может подсунуть свинью нашим замерам. Во-вторых, даже если всего этого не произойдёт, мы ведь дополнительно замеряем время операций сравнения и инкремента (я про i < MAX_ITER_N; i++). Нехорошо.
Давайте тогда сделаем следующим образом:
int g(){ int x = 0; for(int i = 0; i < MAX_ITER_N; i++) x = i; return x; } int f(){ int x = 0; for(int i = 0; i < MAX_ITER_N; i++) x = x + i; return x; } … begin_t = gettime(); res = g(); end_t = gettime(); bad_delta_time = end_t — begin_t; begin_t = gettime(); res = f(); end_t = gettime(); clean_time = end_t — begin_t — bad_delta_time;
Таким образом, мы вплотную приблизились к тому, чтобы мерять «чистое» время операций. А теперь, чтоб получить количество операций в секунду, мы количество выполненных итераций на затраченное время.
Ну, вроде, основные моменты методики объяснил (если прочитать мой код, там немного иначе), теперь перейдём к результатам.
Важный момент — на Codeforces используется 32-битный компилятор, поэтому бенчмарк был скомпилирован с опцией -m32. Насколько мне известно, на серверах Codeforces используются процессоры Intel, поэтому результаты на своём Intel i5 2430M я считаю более-менее соответствующими тем, что в теории могут быть на Codeforces.
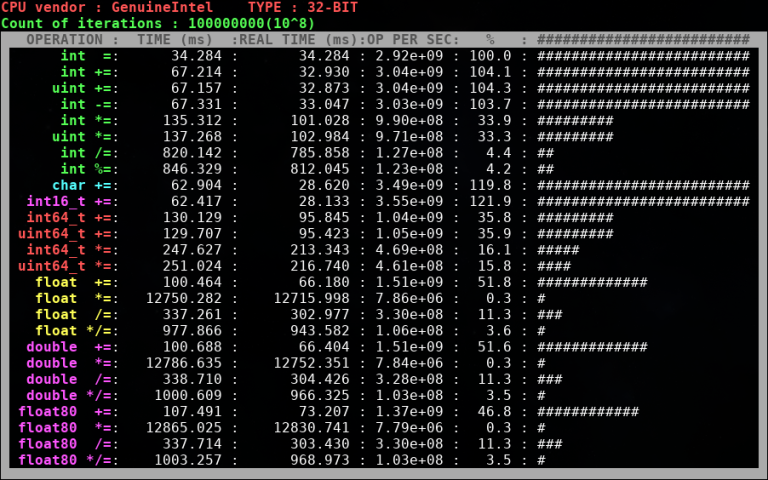
Ну, во-первых, 64-битные типы данных уступают примерно в два раза по производительности 32-битным типам. Во-вторых, операции деления и взятия по модулю намного тяжелее умножения (несмотря на то, что при реализации длинки асимптотика и у деления, и у умножения O(N^2). Ну и для тех, кто сомневался в том, что знаковые и беззнаковые типы одинаковы по производительности — видно, что таки одинаковы.
Возможно, у вас возникнет вопрос по поводу умножения чисел с плавающей запятой (с чего это вдруг «умножение + деление» по времени занимает меньше, чем просто «умножение», причём существенно). Тут объяснение есть. В моём бенчмарке при умножении дробных чисел на i-ой итерации в переменной-результате хранится, по сути, значение i!. Проблема в том, что начиная с некоторого момента это число не помещается в действительный тип и после этого тип хранит особенное значение inf. Понятия не имею, почему работа с этим значением медленнее, чем с «обычными», но факт остаётся фактом.
Для любознательных
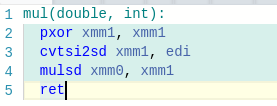
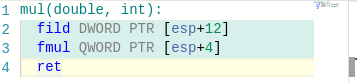
При компиляции с -m64 умножение float и double (но не умножение float80) работает сравнимо с другими операциями над этими типами. Единственное объяснение, которое я нашел — при компиляции с -m64 работа с этими типами происходит через регистры, а при -m32 почему-то напрямую через память. Пруфы вот:
Код на С++
!(/predownloaded/91/7c/917c8a58f0daa06f6dee1a7b2fac9bd42e64310e.png)
То, во что компилируется код при использовании -m64
То, во что компилируется код при использовании -m32
Если кто-то знает, в чём конкретно причина — буду рад услышать.
Надеюсь, эта информация кому-то поможет.
| Производительность суперкомпьютеров | ||
|---|---|---|
| Название | год | флопсы |
| флопс | 1941 | 100 |
| килофлопс | 1949 | 103 |
| мегафлопс | 1964 | 106 |
| гигафлопс | 1987 | 109 |
| терафлопс | 1997 | 1012 |
| петафлопс | 2008 | 1015 |
| эксафлопс | 2021 или позже | 1018 |
| зеттафлопс | не ранее 2030 | 1021 |
| иоттафлопс | н/д | 1024 |
| ксерафлопс | н/д | 1027 |
 Рост производительности суперкомпьютеров во флопсах
Рост производительности суперкомпьютеров во флопсах
FLOPS (также flops, flop/s, флопс или флоп/с; акроним от англ. FLoating-point Operations Per Second, произносится как флопс) — внесистемная единица, используемая для измерения производительности компьютеров, показывающая, сколько операций с плавающей запятой в секунду выполняет данная вычислительная система. Существуют разногласия насчёт того, допустимо ли использовать слово FLOP (или flop или флоп, от англ. FLoating point OPeration), и что оно может означать. Некоторые считают, что FLOP (флоп) и FLOPS (флопс) — синонимы, другие же полагают, что FLOP — это просто количество операций с плавающей запятой (например, требуемое для исполнения данной программы).
Поскольку современные компьютеры обладают высоким уровнем производительности, более распространены производные величины от флопс, образуемые путём использования приставок СИ.
- 1/5 Просмотров:5 047 8 525 103 123 349 805 223 263
- ✪ Как измерить производительность компьютера
- ✪ FLOPS.Измерение производительности
- ✪ Индекс производительности Windows
- ✪ Всё о Российских Процессорах
- ✪ Какая должна быть температура процессора
- 1 Флопс как мера производительности
- 1.1 Границы применимости
- 1.2 Пиковая производительность
- 1.3 Причины широкого распространения
- 2 Обзор производительности реальных систем
- 2.1 Суперкомпьютеры
- 2.1.1 Уно
- 2.1.2 Кило
- 2.1.3 Мега
- 2.1.4 Гига
- 2.1.5 Тера
- 2.1.6 Пета
- 2.1.7 Экса
- 2.2 Процессоры персональных компьютеров
- 2.3 Количество операций FLOP за такт для разных архитектур
- 2.4 Процессоры карманных компьютеров
- 2.5 Распределённые системы
- 2.6 Игровые приставки
- 2.7 Графические процессоры
- 2.8 Человек и калькулятор
- 2.1 Суперкомпьютеры
- 3 См. также
- 4 Примечания





